
Recommendations – Right from birth, our lives are driven by recommendations. Some we accept and some we choose to ignore. Some make us ponder, some sound outright ridiculous. Recommendations come in all shapes, sizes and flavours. When your favourite map app suggests a “recommended” route to reach you destination, or when you ask your waiter for a recommendation to order your food at a restaurant, or when social media shows your buddy’s feedback on the CUDA core GPU he got for his new gaming machine. Recommendation systems are integral part of our modern lives and hide in plain sight making our lives better and our choices more meaningful. Market Basket Analysis is one way of providing recommendations based on general consumer buying/usage patterns. It is a science of studying user behaviour data and providing recommendations based on matching situations.
Market Basket Analysis, also known as MBA, as the name suggests, is an analysis made on items frequently bought together in a single transaction by users in order to predict the buying pattern of majority of users and decide on providing proper recommendations in the form of either arranging associative items together or by providing information regarding the pattern of items bought together in previous transactions by other customers. This need not be just a buying pattern. This could be applied to any kind of usage/activity which has multiple distinct entities that can be grouped as a identifiable transaction. Implementing an Market Basket Analysis and exploring the insights is not necessarily a complex process. In this article, I have tried to give you a high level idea of what it takes to implement a simple algorithm using Python packages to get you started on Market Basket Analysis. Future articles will cover implementation details with code examples and will also explore the limitations of some of these algorithms and how I have used Neural Networks to expand the feature set for prediction/recommendation along with overcoming performance bottle necks when dealing with large sets of data.
A few popular algorithms are available to solve Market Basket Analysis or what can be generalized as Associative Rule Mining. One that renders well for programming implementation is Apriori. Apriori can be implemented in various statistical programming languages but Python and R would reduce complexities offered by the algorithm with their code readability built on simple syntaxes. First, to start off with the dataset, more than any other features in dataset, there should be two important features which are useful for analysis – transaction ID and the items in that particular transaction ID. Although there could be many more features which can be used for deeper analysis, these two features are most essential for basic implementation of Market Basket Analysis. Python would be my first choice and the use of Jupyter Notebook makes things simpler. Pandas and numpy libraries are used exclusively used to solve any machine learning problems like MBA. In R, it can be executed using R studio. arules and arulesviz are two packages exclusively to form associations in the R world.
First step is to import those packages and import the dataset. The second step is to define support. Support is defined as the probability of an item being bought in the particular transaction. One has to decide on a minimum support before proceeding with processing of dataset. Minimum support can be decided based on size of dataset and number of unique items in the dataset. The next step is to generate single candidates i.e. the unique items in the entire dataset and calculate support for each item by calculating the number of occurrences of particular item in a transaction and if its support surpasses the minimum support considered, it can be allowed for next level of two candidate generation or else those items are not considered for arriving at the recommendations. We now move on to the second level candidate generation where those items, which passed the first level of support screening, will be clubbed into pair of two, without any repetition of items in anyway and support value is calculated for them also and this process is repeated until formation of maximum level of candidate generation which the algorithm can deliver.
After all these steps, there comes the stage of deciding associations for set of item sets which are qualified for providing recommendations on the basis of passing the test of support. A measure of trust, defined by the business stake holders, is required, on these recommendations. This trust is provided by a term called “Confidence”. Confidence is based on conditional probability which is defined as the possibility of second event to occur when first event had already been happened.
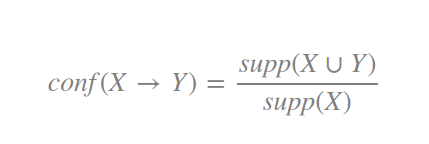
Here confidence is defined as the chances of Y being purchased when item X is purchased. Like that, confidence value has to be calculated for item sets available after candidate generation and support elimination.
For example, if Confidence ({Bread, Butter} –> {Jelly}) = 0.75, it implies that 75% of orders containing Bread and Butter, also contains Jelly. Like support, confidence has to be set to a minimum value. A confidence level of around 70% would imply a very strong association and provide a strong recommendation. Item sets whose confidence value is above minimum value, can be called as rules and could be used to make recommendations to improve conversion or to make any business decisions like stocking things in a warehouse to setting up questions in a test.
Recommendations can be strengthened further by considering external and hyperlocal factors like weather, time of purchase, GDP, etc., to get deeper insights on consumer influencers and mind-set when a transaction is made and thereby recommend better products/actions to improve sale, increase customer satisfaction, improve retention, lessen churn and increase conversion. More on this in the next part.



{kind=link}