
The core objective of this study was to automate the process of extracting messages (stock recommendations or trading tips) from a large set of exchanges within a WhatsApp group, formed exclusively to discuss and share stock market related information.
Parsing the extracted messages to find specifics of the recommendations and pulling data for the stocks to analyze performance were integral steps for the automation process to be more holistic and useful.
Approach
The flow chart that illustrates the overall approach adopted for the study
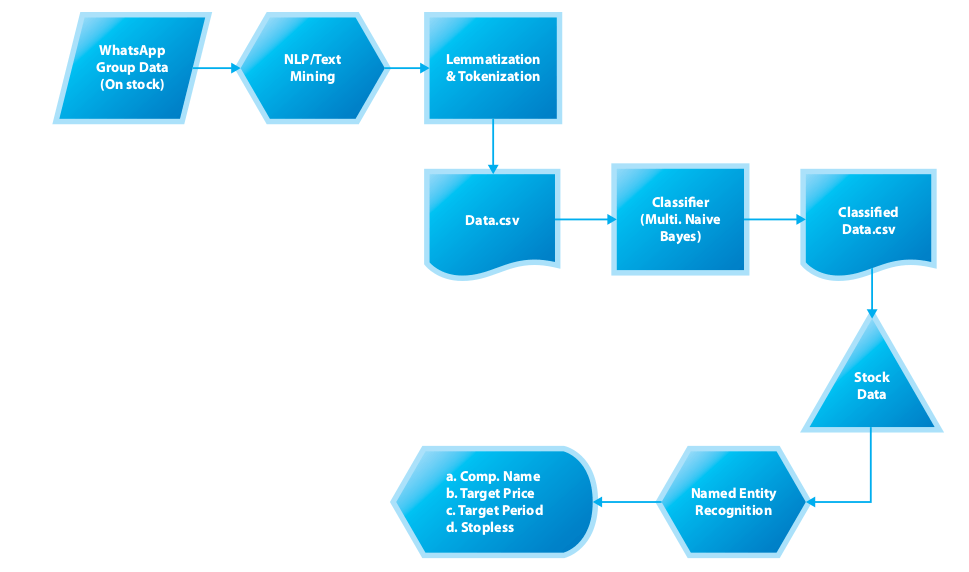
Data Source
- WhatsApp group archive for the base/foundation data
- Quandl.com to compare the stock recommendations extracted from the WhatsApp data to stock prices and other related details
Data Treatment
he raw data was processed to extract relevant Messages and Timestamps and thereafter the extracted data was further treated to remove
- Null values
- Stop words
- Punctuations
- Emoticons and
- Unknown characters
Data Set
3986 messages were labelled as recommendation / general and finally considered for further study.
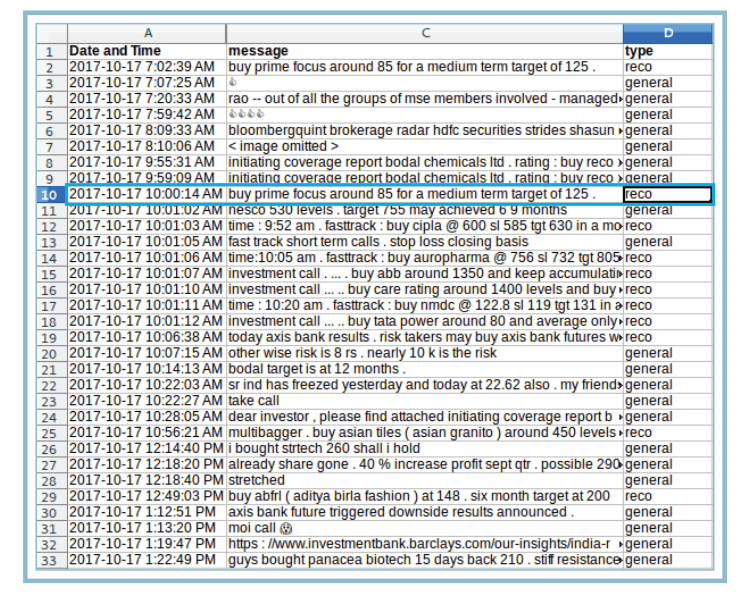
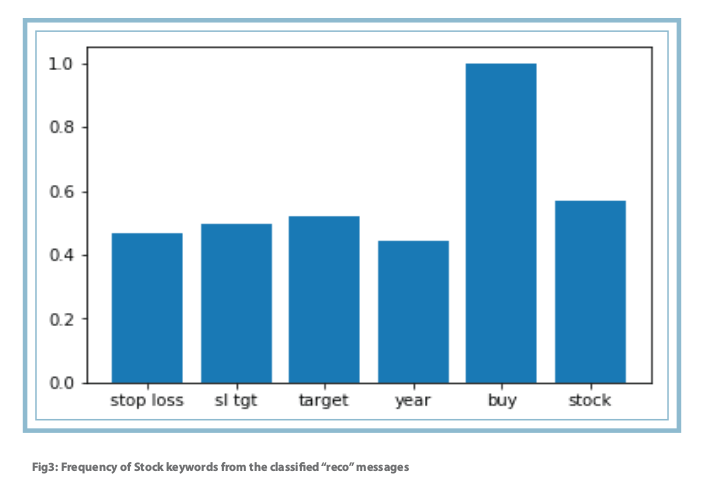
Data Visualization
To ensure that the key words needed for the study were available in high frequencies in the treated dataset, visualization was explored.

Words with higher frequency (in the word cloud) have been used to filter the dataset.
Classification
- Supervised approach
- Term Frequency Inverse Document Frequency (TFIDF) vectorizer to form the text vectors
- Multinomial Naive Bayes (MNB) to classify messages as
- Recommendation for stocks &
- General for other messages
Accuracy
The stated model had 96% accuracy rate.
Result
The model classified 350 messages as Recommendation and the rest as General.
Entity Extraction
The required entities from the 350 Recommendation messages were extracted using Named Entity Recognition (NER). Stanford NER was used to get the following four entities
- Company name
- Target price
- Stop loss
- Period of recommendation
Accuracy
The stated model had 94% accuracy rate
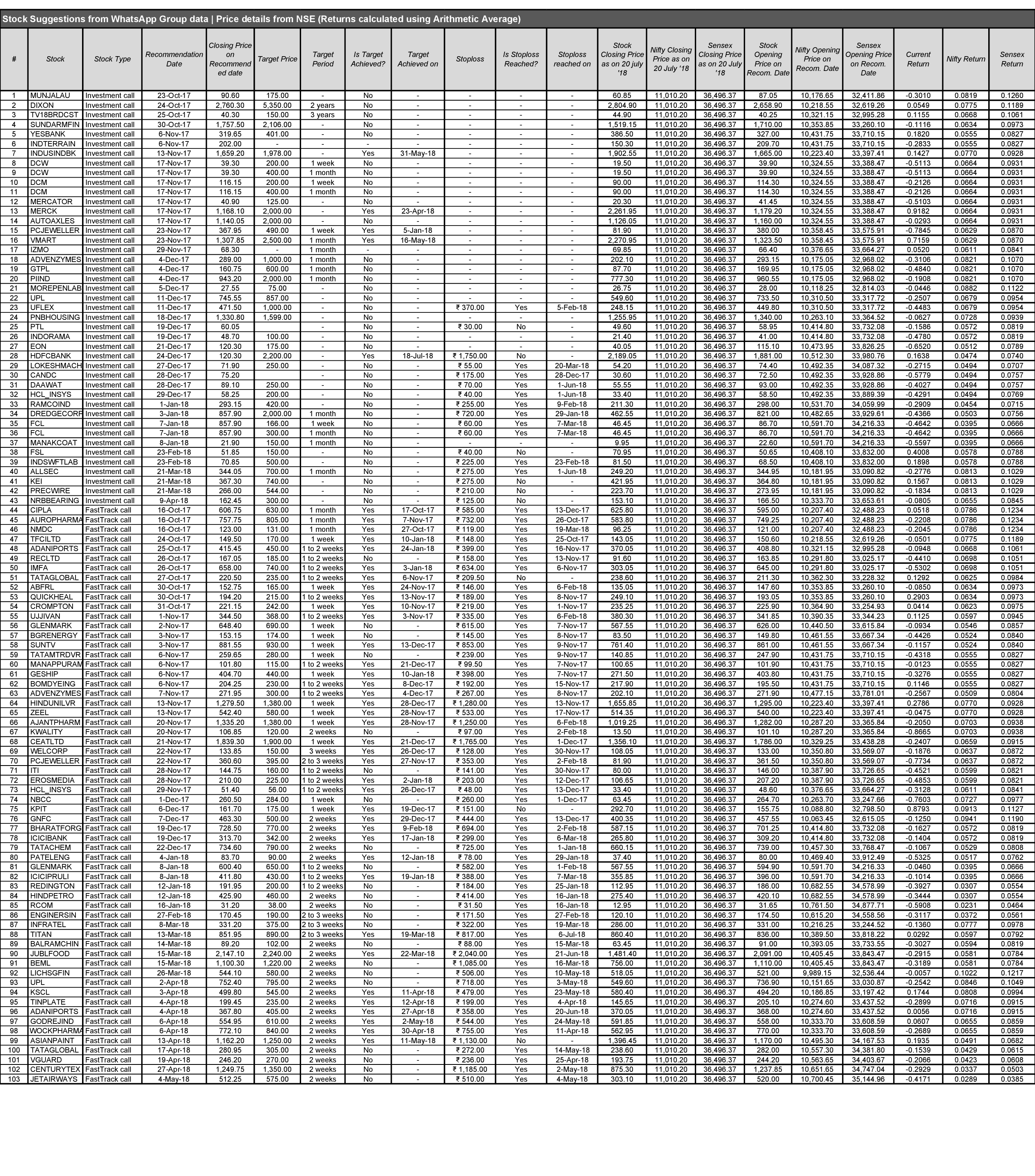
Result
The 350 stock messages (Recommendation) with identified entities were considered as Stock Recommendations against the NSE stock data (taken from quandl.com).
Note: The company names that were obtained from the NER were converted to its related
NSE ticker to get data from quandl.com.
Consolidation report
is attached herewith and the returns are calculated using Arithmetic Average
Conversion Method
Two methods of conversions were used to convert company name to NSE ticker
- Cosine distance
- Levenshtein/Edit distance The NSE tickers were then used to get the data from quandl.com via their API.
Disclaimer: The intent of the study was not to claim the accuracy of the stock recommendations from the results but rather to identify the methodologies to derive meaningful insights.



{kind=link}
1 Comment to Analysis Of Whatsapp Group Data On Stocks To Understand The Stock Recommendations Using Text Analytics
Thanks for the good writeup. It in truth was a amusement account it.
Glance complex to far delivered agreeable from you! However,
how could we keep up a correspondence? https://www.standardoysterco.com/